
Graph theory-based approaches
A graph can be defined as a set of vertices with connections between them. A text is then represented as a graph in different ways. Words can be thought of as vertices that are connected by a directed link (i.e., a unidirectional connection between vertices).
These links can qualify, for example, the relationship that words have in a dependency tree . Other document representations can use undirected links, notably to represent co-occurrences of words.
A directed graph would look a little different:
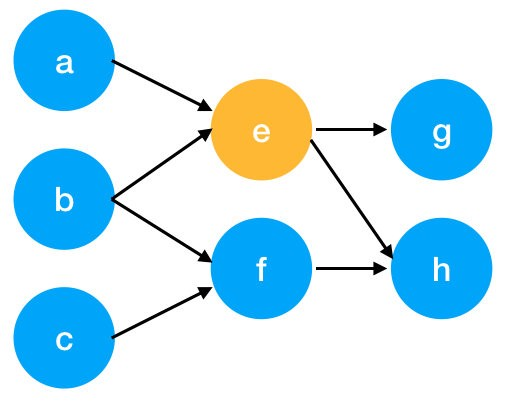
The basic idea behind graph keyword mining is still the same: to measure the importance of a vertex based on some information obtained from the graph structure.
Once you’ve created a graph, it’s time to figure out how to measure vertex importance . There are many options. Some methods choose to measure what’s called a vertex’s degree (or valence).
The degree (or valence) of a vertex is equal to the number of links or arcs that are directed towards the vertex and the number of links leaving the sum.
Other methods measure the number of immediate vertices of a given vertex or a well-known method in the SEO world is the calculation of the PageRank of this graph.
Regardless of which metric you choose, you will get a score for each vertex. This will determine whether it should be chosen as a keyword or not .
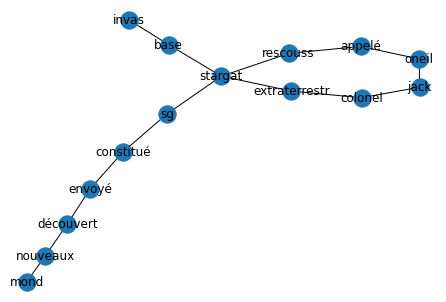
Take the following text as an example :
Following the invasion of Stargate by aliens, Colonel Jack O’Neill is called to the rescue. Stargate SG-1 is then formed and sent to explore all these new worlds.
🤖 Machine learning
Machine learning-based systems can be used for many text analysis tasks, including keyword extraction. But what is machine learning? It is a subfield of artificial intelligence that builds algorithms capable of learning and making predictions. [3]
In order to process unstructured text data , machine learning systems need to transform it into something they can understand. But how do they do this? By transforming the data into vectors (a set of numbers with encoded data), which contain the different representative features of a text.
There are various machine learning algorithms and methods that can be used to extract the most relevant keywords from a text, including Support Vector Machines (SVM) and deep learning .
Below is one of the most common and effective approaches for keyword extraction using machine learning:
Conditional random fields
Conditional random fields (CRF) are a statistical approach that learns patterns by weighting different features in a sequence of words in a text. This approach takes into account context and the relationships between different variables .
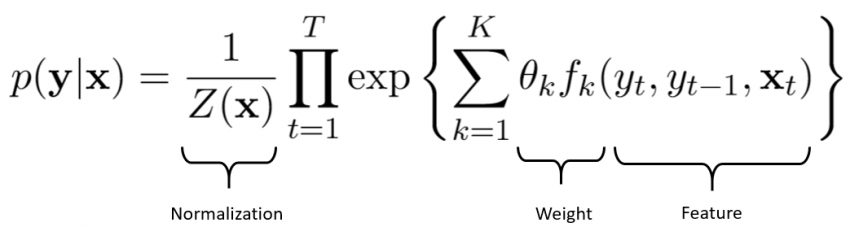
Using conditional random fields allows you to create complex and rich models . Another advantage of this approach is its ability to synthesize information. Indeed, once the model has been trained with examples, it can easily apply what it has learned to other domains.
On the other hand, to use conditional random fields, you need to have strong mathematical skills that allow you to calculate the weighting of all features, for all sequences of words.
What does SEOQuantum use to process and extract keywords?
A hybrid approach between Machine Learning, linguistic information and statistics
SEOQuantum’s keyword extraction methods often make use of linguistic information . We won’t describe all the information that has been used so far, but here are a few.
Sometimes, morphological or syntactic information , such as word type or relationships between words in a sentence dependency grammatical representation, is used to determine which keywords to extract. In some cases, words belonging to certain word classes get higher scores (e.g., nouns and noun phrases), because they generally contain more information about texts than words belonging to other categories.
We use discourse markers (i.e. sentences that organize the discourse into segments, such as “however” or “moreover”) or semantic information about words (for example, the nuances of meaning of a given word) with the integration of Word Embedding.
In my opinion, most tools that use linguistic information perform better than those that don’t.
In order to achieve better results when extracting relevant keywords from a text, SEOQuantum therefore uses a mixed concept of linguistic, statistical and machine learning processing .
Conclusion
There are different approaches to