
🤔 How is keyword mining useful?
Considering that over 80% of the data we generate every day is unstructured—that is, it’s not organized in a predefined way and is therefore difficult to analyze and process—keyword mining is very appealing. It’s a powerful tool that can help you understand data about a page, customer reviews, a comment, etc. In short, any unstructured data.
Some of the major benefits of keyword mining include:
Scalability
Automated keyword extraction allows you to analyze as much data as you want . While you could read the texts yourself and identify keywords manually, this would be time-consuming. Automating this task gives you the freedom to focus on other tasks.
Consistent criteria
Keyword extraction works based on predefined rules and parameters. You won’t get any inconsistencies . These are common when analyzing text manually.
Real-time analysis
You can perform keyword mining on social media posts, customer reviews, or customer support tickets to gain insights into what’s being said about your product in real-time.
In short…
Keyword mining allows you to extract relevant information from a large amount of unstructured data. By extracting key words or phrases, you can get an idea of the most important words in a text and the topics covered.
Now that you understand the concept of keyword mining and have a good understanding of how it works, it’s time to understand how it works. The following section explains the fundamentals of keyword mining and introduces you to the different approaches to this method, including statistics, linguistics, and machine learning.
🔎 How does keyword extraction work?
Keyword mining makes it easy to identify relevant words and phrases from unstructured text. This includes web pages, emails, social media posts, instant messaging conversations, and any other type of data that isn’t organized in a predefined way.
There are several different methods you can use to automatically extract keywords. From simple statistical approaches that detect keywords by counting word frequencies, to more advanced approaches made possible by machine learning, you can implement the model that best suits your needs.
In this section, we will examine different approaches to keyword extraction, with an emphasis on machine learning-based models . [2]
Simple statistical approaches
Using statistics is one of the simplest methods to identify key words and phrases in a text.
There are different types of statistical approaches , including word frequency, word collocations and co-occurrences, TF-IDF (term frequency-inverse document frequency), and RAKE (Rapid Automatic Keyword Extraction).
These approaches don’t require training data to extract the most important keywords from a text. However, since they rely on statistics, they may overlook relevant words or phrases that are only mentioned once. Let’s take a closer look at these different approaches:
Word frequency
Word frequency is the process of listing the words and phrases that appear most frequently in a text . This can be very useful for a variety of purposes, from identifying recurring terms in a series of product reviews to finding the most common issues in customer service interactions.
However, word frequency-based approaches treat documents as a mere “collection of words,” leaving aside crucial aspects related to semantics, structure, grammar, and word order . Synonyms, for example, cannot be detected by this method.
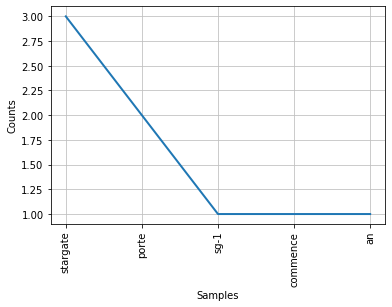
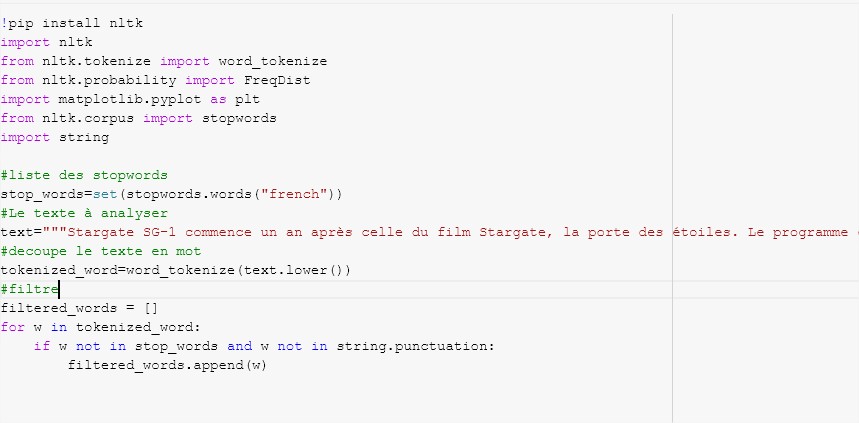
Here is an excerpt of the Python code to obtain the frequency of words in a text (you can find the notebook below):

Collocations and co-occurrences of words
Also known as n-grams, word collocations and co-occurrences can help you understand the semantic structure of a text . These methods consider each word as unique.
Differences between collocations and co-occurrences:
Collocations are words that are often combined. The most common types of collocations are bigrams (two words that appear adjacent to each other, such as “web writing” or “digital agency”) and trigrams (a group of three words, such as “easy to use” or “public transport”).
Co – occurrences , on the other hand, refer to words that tend to co-occur in the same text. They do not necessarily have to be adjacent, but they do have a semantic relationship.

The TF-IDF